2020年代前半から生成AIが一世を風靡しましたが、生成AIの基礎となるLLM(Large Langage Models, 大規模言語モデル)を構築するために、言葉を数値に置き換えることが非常に重要です。コンピュータは数値を扱うことができますが、文字を直接扱うことはできないからです。
そして、単に数値化するといっても、文字を文字コードに置き換えるだけでは、その数字の列に何の意味もないため、単語をベクトル化することが行われています。なお、最近のAIブームよりもずっと前から、AI(自然言語処理)の領域では、形態素解析(≒単語)といって意味を持つ最小単位に区切った上で、意味理解や次にくる言葉の予想が行われていたため、単語(形態素)を数値化しようという考え方自体は、従前の研究の流れからきているものです。
そして、Tomas Mikolovらによって発表されたword2vec(Efficient Estimation of Word Representations in Vector Space, https://arxiv.org/abs/1301.3781)
によって単語をベクトル化しニューラルネットワークで扱う手法が提案されました。このような考え方が、LLMの発展に大きく寄与しているものと思います。
Word2vecは単語を分散表現で表す、などと言われます。分散といわれると、正規表現の分散?とか難しくなりますが、単語をベクトル表現で表す、という程度の意味合いで捉えればよいのかと思います。Word2vecでどうベクトル表現にするかはいろいろなサイトで説明されていると思いますので、検索いただければよいかと思いますが、概要としては、CBOWとskip-gramの2種類の方法があります。
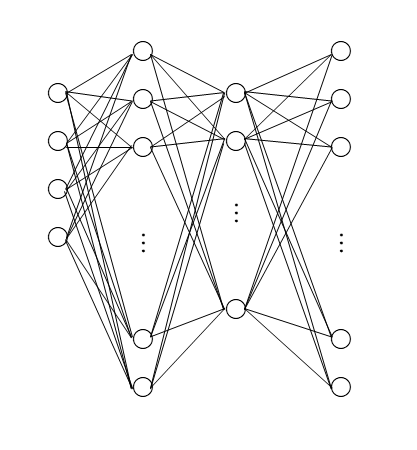
【CBOW】よくある説明に従えば、W1,W2,…W10000の1万単語がある場合、それぞれWNはN番目の要素が1,他の要素が0のベクトルをone-hotベクトルとします。そして、2層の中間層があるニューラルネットワークで、1層目を10000次元(単語数の数)、2層目を200次元(数百程度にするのが一般的)にし、1層目の重みはすべて1とします。
CBOWの入力を、対象となる単語の前後2単語とすると、
W1 W2 W3 W4 W5の単語列が学習データとして存在し、
入力層は、W1 W2 W4 W5が入力され、正解はW3、という組合せが学習データになります。
そうすると、中間層の1層目は、4×10000次元の全てが1の行列で、中間層の2層目は、10000×200の重みを表す行列となり、これが学習されていくことになります。
最終的に、パラメータが更新された中間層の2層目の重みは、10000×200次元で表されており、これはすなわち、10000単語がそれぞれ200次元のベクトルで表すことが可能となっており、単語のベクトル化が実現できることになります。

【skip-gram】CBOWと逆で、W3が入力のときに、正解をW1 W2 W4 W5として学習していくことになります。
上記の200次元のベクトルは、各次元がそれぞれ何の意味を持っているか分析することはできませんが、それぞれが意味を持っており、「王-男+女=女王」が推論可能な単語のベクトル化を実現することができます。