学習データに著作物を利用した際の生成AI提供事業者の責任
1 著作権法30条の4との関係 著作権法30条の4では、学習データとして著作物を利用することが原則として許容されています。これは、AIの学習時に著作物を利用することは許容されていますが、生成時に許容されているわけではありません。したがって、生成AIの生成時には、著作権法30条の4とは別に、著作権侵害の要件である依拠性、類似性の観点から侵害の成否が問題となります。また、生成AIでは、依拠性について、 […]
1 著作権法30条の4との関係 著作権法30条の4では、学習データとして著作物を利用することが原則として許容されています。これは、AIの学習時に著作物を利用することは許容されていますが、生成時に許容されているわけではありません。したがって、生成AIの生成時には、著作権法30条の4とは別に、著作権侵害の要件である依拠性、類似性の観点から侵害の成否が問題となります。また、生成AIでは、依拠性について、 […]
1 何が有益な情報か 生成AIの精度が日を追うごとに向上し、これからは何かの業務を行うに際しても、AIとの関係は切っても切れない関係になると思われます。その中で、生成AIの性能向上のためには学習データが欠かせません。したがって、あるタスクを実行させようとしたときに、それを人間が行ったデータがあるとすれば、生成AIの学習データとして用いることが可能という観点では非常に重要なデータです。例えば、取引デ […]
日本では、AIの学習データのために第三者の著作物を利用する場合、著作権法30条の4の規定により許容されることが多いです(こちらの記事でも書いた通り)。 そして、著作権法30条の4を前提にすると、学習データに用いる著作物が海賊版サイトのように不正に取得されたソースから取得されたものであっても、基本的に許容されると考えられます。 一方で、例えばEUでは、DSM指令第4条によって、合法的にアクセスでき […]

事業者間で取引する際には、秘密保持契約書(NDA:Non-Disclosure Agreement / CA:Confidentiality Agreement)を締結することがあります。秘密保持契約書は、契約書は割合と定型的なものが用いられますが、立場によってどうすべきか、というものは変わってきますので注意が必要です。なお、公的機関が公表しているひな形としては、中小企業庁の以下のようなものがあり […]
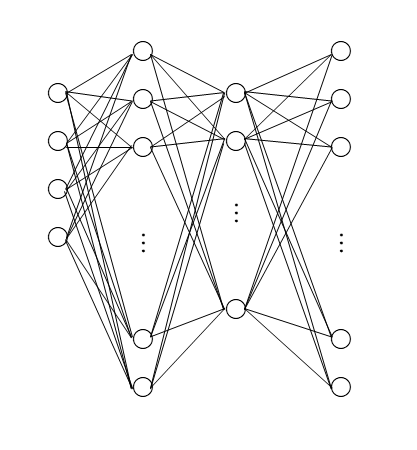
2020年代前半から生成AIが一世を風靡しましたが、生成AIの基礎となるLLM(Large Langage Models, 大規模言語モデル)を構築するために、言葉を数値に置き換えることが非常に重要です。コンピュータは数値を扱うことができますが、文字を直接扱うことはできないからです。 そして、単に数値化するといっても、文字を文字コードに置き換えるだけでは、その数字の列に何の意味もないため、単語をベ […]
AIを学習させるために、スクレイピングをしてデータを取得したいという場面があります。そして、スクレイピングに際して、著作権法上の問題や契約上の問題について触れましたが、その他にも、業務妨害という観点でも気を付ける必要があります。例えば、スクレイピング先のサーバーに高負荷をかけてしまうと、業務妨害罪等に該当する可能性(刑法233条の偽計業務妨害罪、刑法234条の威力業務妨害罪、刑法234条の2の電子 […]
スクレイピングによりデータを集める場合、法律上の規制に該当することは限られた場面になりますが、契約に違反しないか、という点も気を付ける必要があります。 1 利用規約 インターネット上のデータにアクセスする際に、サイトに利用規約が掲げられていることがあります。利用規約には主に、一方的に利用規約のみが示されているケース(会員登録がないために同意の意思表示をする場面がないものの利用規約が定められているよ […]
生成AIで使われるような LLM(大規模言語モデル) は、膨大なデータを学習することで高い性能を実現しています。 では、その学習データとして、インターネット上の文章をスクレイピング(自動収集)して使うことは、著作権法との関係で問題ないのでしょうか。 結論から言うと、他人の著作物をLLMの学習データとして使うこと自体は、原則として適法です。 ただし、学習後にAIが出力する内容には注意が必要です。 な […]
近年、AI(Artificial Intelligence:人工知能)の進化は驚くほどのスピードで進んでいます。人間のような完全な思考は難しい部分もあるものの、決められた作業であれば人間より高速かつ正確にこなし、応用的な処理や人間には不可能な分析さえ可能になりつつあります。このようなAIの進歩を支えている「コア」は何でしょうか。多くの方がLLM(Large Language Models:大規模言 […]